
算法系列(三)蓝桥杯_算法高阶(一)
算法高阶
本部分算法难度较高,建议读者充分掌握算法基础之后再来学习。
目前以视频的方法为主,等蓝桥杯考完之后按照labuladong或者是考研的方法写代码。
我的仓库使用指南
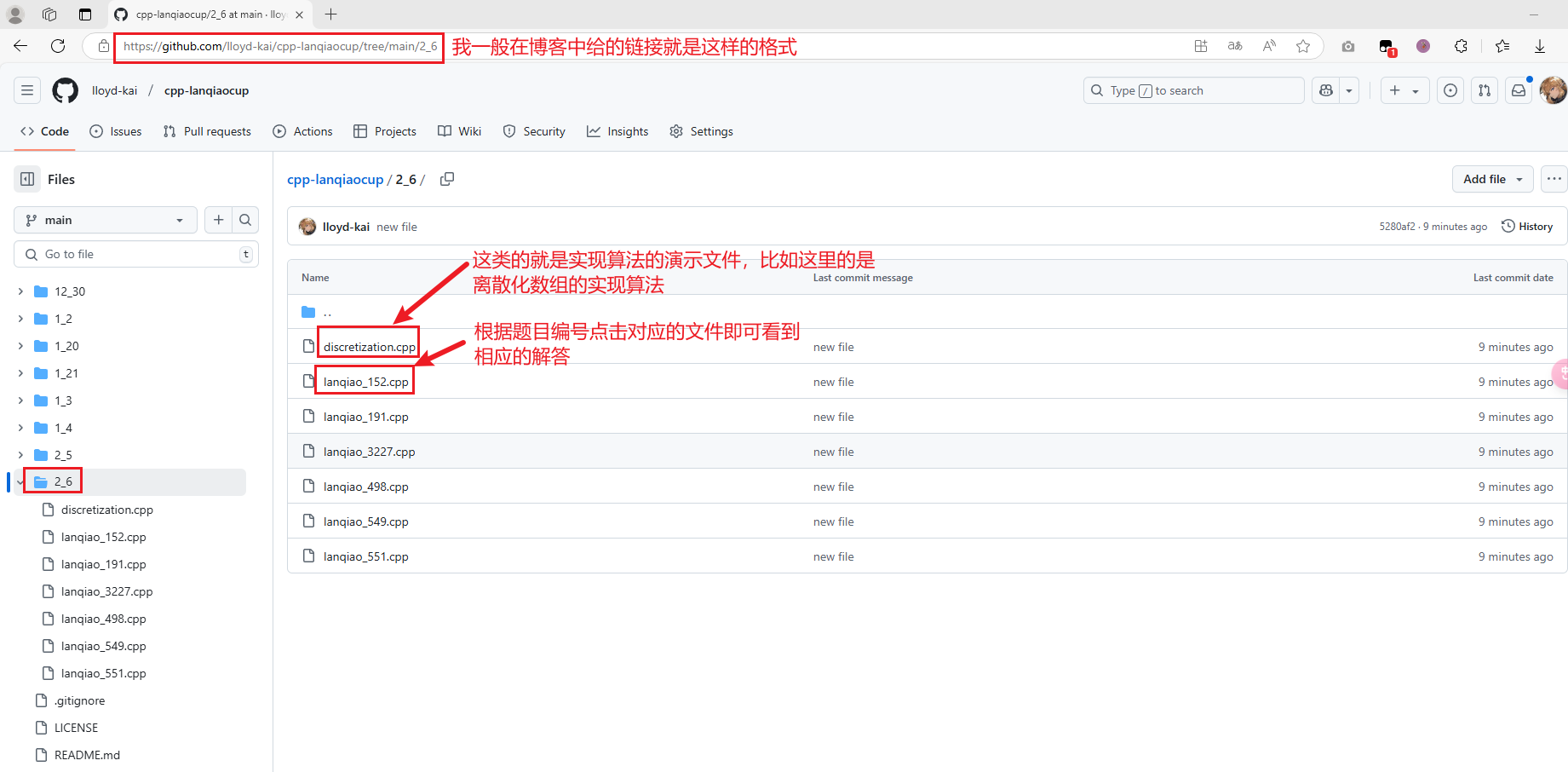
我的仓库链接格式如下:https://github.com/lloyd-kai/cpp-lanqiaocup/tree/main/1_20 其中1_20表示的是日期(一般是2025),里面的文件就包含对应题目的解答(均通过对应题目的测试)或者是算法实现,其中文件名lanqiao表示 是蓝桥杯官网上的题目,_ 后面的数字是蓝桥杯的题目编号,可以找到对应的蓝桥杯的题目,比如题目链接是https://www.lanqiao.cn/problems/498/learning/?page=1&first_category_id=1&problem_id=498 problems斜杠后面的数字498 就是对应的题目编号,你就在我指定链接下面的文件夹下按照lanqiao_题目编号.cpp 这样的格式找对应文件,就可以看到对应题目的解答代码。
搜索
回溯法
【概念】:回溯法一般使用DFS(深度优先搜索)实现,DFS是一种遍历或搜索图、树或图像等数据结构的算法,当然这个图、树未必要存储下来(隐式处理就是回溯法),常见的是通过某种关系构造出的搜索树,搜索树一般是排列型搜索树(总节点个数一般为n!级别)和子集型搜索树(总节点个数一般为2^n级别)。
排列型就是每次枚举选哪个,子集型就是对于每一个元素选或不选(结果与顺序无关)。DFS从起始节点开始,沿着一条路径尽可能深入地搜索(一条路走到黑),直到无法继续为止,然后回溯到前一个节点,继续探索其他路径,直到遍历完整个图或树。DFS使用栈或递归来管理节点的遍历顺序,一般使用递归。很多时候DFS和回溯法不必过度区分。
【实现】实际上的回溯法比较灵活,需要根据题意要求来具体分析。vis[i]表示数字i是否使用过,也经常被用于表示
某个元素是否使用过a[]]存放结果,当dep深度=n+1时说明n层都已经算完了,直接输出结果。子集型搜索树模板结构类似,就是在往下走时候只有两条边,表示“选或不选当前这个元素
【例题】
- 1.N皇后问题 - 蓝桥云课 非常经典的题目
【分析】:首先可以肯定的是,每一行必然有且仅有一个皇后(因为不可能出现两个皇后在同一行),于是就通过枚举每一层皇后的位置来搜索所有可能解即可。每放置一个皇后就将对应的米字型区域设置为“禁区”(vis[]数组),后面的皇后就不能放在“禁区”里,回溯的时候将禁区取消掉。为了正确维护“禁区”,不能使用bool数组来表示禁区,需要使用int数组,表示这个位置被“多少个皇后占用了”,当占用数为0时表示“禁区解除”。层数到n+1时表示找到了一个解,不可行的解都到不了第n+1层
跑dfs求最大的环,可以用时间戳(dfn),将走过的地方标记一个时间戳(即第几步走到的)后续搜索中,每次开始时更新最小时
戳 (mindfn),如果走到已经走过的点就必须停下,然后根据时间戳的合法性来更新最大值。
这里直接统计岛屿的数量比较复杂,可以将不同的岛屿标记(先用dfs将不同的岛屿染上不同的颜色),然后计算最后剩下的岛屿颜色有多少种,再减去就是被淹没的岛屿数量。
本部分例题解决实现代码链接:点击此处
剪枝
【概念】:剪枝更偏向于技巧性,是对回溯法的优化。其实就是将搜索过程当中一些不必要的部分直接剔除掉,因为搜索过程构成了一棵树,剔除不必要的部分,就像是在树上将树枝剪掉,故名剪枝。
在实际使用中剪枝是通过一些约束条件使得搜索提前终止实现的。
【例题】:
- 1.数字王国之军训排队 - 蓝桥云课 如果这一题不使用剪枝的方法就会导致最后一个测试用例超时
在做这一类题的时候,关键在于将“若干””队“等词语理解成树的每一层(你想想看是不是这样)而不是简单的多个数组,那么就会自然而然想到使用DFS解决问题。注意树一般是用二维数组数据结构来存储的。
不妨规定我们构造出的3元组是递增的,那么在搜索过程中我们就可以通过计算得到当前这个位置的上限(剪枝的关键dfs过程中记录乘积,因为乘得越多数字越大,当乘积mul>1e6时直接返回(乘积很容易就超过1e5,数字较大时层数就两三层)同时还能记录一下n-1条边的长度和sum,最后一条边必须小于sum.最后用前缀和快速进行区间查询。
- 1.特殊的多边形 - 蓝桥云课 方法和特殊的三角形一样 这道题的通用性比上一题更强。
本部分例题解决实现代码链接:点击此处
记忆性搜索(带备忘录的搜索)
【概念】:就是将搜索过程中会重复计算且结果相同的部分保存下来,作为一个状态,下次访问到这个状态时直接将这个子搜索的结果返回,而不需要再重新算一遍。通常会使用数组或map来进行记忆化,下标一般和dfs的参数表对应。需要注意的是使用记忆化需要保证重复计算的结果是相同的,否则可能产生数据失真。
【例题】:
- 斐波那契数列对1e9+7取模。如果使用传统的递归可以做,但是如果要求的位很大的话会超时。我们可以观察到每一次计算某一位的斐波那契值的时候都把前面计算过的又计算了一遍,存在重复计算的现象,不妨将重复计算的值存储起来,下次要使用的时候如果有就直接使用,这样大大减少时间。
示例代码如下
1 |
|
【例题】
本部分例题解决实现代码链接:点击此处
动态规划
背包问题
【概念介绍】:01背包模型:有一个体积为V的背包,商店有个物品,每个物品有一个价值v和体积w,每个物品只能被拿一次,问能够装下物品的最大价值。
【实现】:这里每一种物品只有两种状态即“拿”或“不拿”。设状态dp[l]表示到第i个物品为止,拿的物品总体积为j的情况下的最大价值。我们并不关心某个物品有没有被拿,只关心当前体积下的最大价值。转移方程为:dp[i][j]=max(dp[i-1][j],dp[i-1][j-w]+v);如果不拿物品i,那么最大价值就是dp[i-1][j],如果拿了就是从体积j-v转移过来,体积会变大w,价值增加v最后输出dp[n][V];
【例题】:
01背包的优化:首先有dp[[i][j]=dp[i-l][j],相当于将dp[i-1]复制给dp[i],然后dp[i][j]=max(dp[i][j],dp[i-1][j-w]+v),每次的下标都是从小的转移到大的,于是我们可以将第一维度给优化掉,直接当做个数组,然后每次更新时,从后往前更新,这样避免了用新数据来更新新数据。即变为:dp[j]=max(dp[j],dp[j-w]+v),dp[j]表示此时物品总重量为j的情况下的最大价值
优化后的代码
1 |
|
- 1.背包与魔法 - 蓝桥云课 对于每个物品有3种选择,可以不选、选但不用魔法、选且用魔法。有点像是之前的那个喷气背包题目
背包问题的解决代码很少,但是其中蕴含的算法和数学思想很多,读者需要多写多理解才能体会其中的精神。
本部分例题解决实现代码链接:点击此处
单调队列多重背包
【介绍】:有N种物品和一个容量是V的背包,每种物品数量有限,第i件物品的体积为v[i],价值为w[i],数量为s[i].求解将哪些物品装入背包使得总价值最大
【实现】:最简单的实现(基础版模型) 多重背包就是将每种物品的s个摊开,变为s种相同的物品,从而退化成01背包问题
1 |
|
【优化】:二进制优化,多重背包基础模型的时间复杂度为O(n*s*V),当s较大时,容易超时。为了解决这个问题,我们可以在“拆分”操作时进行一些优化,我们不再是拆分成均为1个物品的组,而是每一组的物品个数为1、2、4、8…,最后剩下的单独为一组,这样一定存在
一种方案来表示0~s的所有情况(想象二进制数的表示方法)在经典模型中,一种物品将被拆分为s组,每组一个,而二进制优化模型中,一种物品将被拆分为约log2(s)组,其中每组个数为1、2、4、8…,例如s=11,将被拆为s=1+2+4+4。这样对拆分后的物品跑一遍01背包即可,时间复杂度为O(n*log(s)*V)。
1 |
|
可以看到,以上算法在时间复杂度上没有优势,那么有没有什么方法能够较好的解决多重背包的问题呢?
当然是有的,就是接下来要讲的单调队列。
【引入】:dp[i][j]表示将前i种物品放入容量为j的背包中所得到的最大价值dp[i][j]=max(不放入物品i,放入1个物品i,放入2个物品i,.,放入k个物品i) 这里k要满足:k<=s,j-k * v>=0.
在不放物品的情况下
放k个物品
推导可得
一维可以滚掉.假设一共有m容量,那么答案为
接下来,我们把dp[0]->dp[m]写成下面这种形式
m一定等于k * v+j,其中0<=j<v,所以,我们可以把dp数组分成j个类,每一类中的值,都是在同类之间转换得到的
也就是说,dp[k*v+j]订只依赖于{dp[j],dp[v+j],dp[2*v+j],dp[3*v+j]…,dp[k*v+j]}因为我们需要的是{dp[j],dp[v+j],dp[2*v+j],dp[3*v+j],…,dp[k*v+j}中的最大值,可以通过维护一个单调队列来得到结果。这样的话,问题就变成了一个单调队列的问题。其中
…
这样,每次入队的值是
1 |
|
【例题】
-
1.小明的背包3 - 蓝桥云课 这一题就是典型的数据量比较小,可以使用多重背包基础模型实现。
二维费用背包&&分组背包
【概念】二维费用背包:有一个体积为V的背包,商店有n种物品,每种物品有一个价值v、体积w、重量m,每种物品仅有1个,问能够装下物品的最大价值。这里每一种物品只有2种状态即“拿0个、1个”,但是需要同时考虑体积和重量的限制。只需要在01背包的基础上稍加改动,将状态转移方程修改为二维的即可,同样是倒着更新。dp[]表示当前体积为i,重量为j的情况下所能拿的物品的最大价值。状态转移方程为dp[i][j]=max(dp[i][j],dp[i-w][j-m]+v);
【例题】:
【概念】分组背包:有一个体积为V的背包,商店有组物品,每组物品有若干个价值v、体积w,每组物品中至多选1个,问能够装下物品的最大价值。前面已经见过这么多背包了,在这里就直接给出分组背包的定义。设状态dp[i][j]表示到第i组,体积为j的最大价值,在这里不能忽略第一维,否则可能导致状态转移错误!状态转移方程为:dp[i][j]=max(dp[i-1][j],dp[i-1][j-w+v);
本部分算法实现与例题解决实现代码链接:点击此处
完全背包
【概念】:完全背包也叫无穷背包,即每种物品有无数个的背包。有一个体积为V的背包,商店有个物品,每个物品有一个价值v和体积w,每个物品有无限多个,可以被拿无穷次,问能够装下物品的最大价值。这里每一种物品只有无穷种状态即“拿0个、1个、2个…无穷多个”。设状态dp[i]表示拿的物品总体积为j的情况下的最大价值。我们并不关心某个物品拿了儿个,只关心当前体积下的最大价值。转移方程为:dp[i]=max(dp[i],dp[i-w]+v),现在就必须使用“新数据”来更新“新数据”,因为新数据中包括了拿当前这个物品的状态,而当前这个物品是可以被拿无数次的。最后输出dp[V]即可。
【例题】:
本部分算法实现与例题解决实现代码链接:点击此处
期望DP
【概念】:这一部分的内容涉及到期望,也就是实验中每次可能的结果乘以其结果概率的总和。其相关性质参考概率论与数理统计。对于一些比较难找到递推关系的数学期望问题,可以利用期望的定义式,根据实际情况以概率或者方案数(也就是概率*总方案数)作为一种状态,将问题变成比较一般的统计方案数问题或者利用全概率公式计算概率的递推问题
【相关数学公式】
全概率公式: B事件发生的概率=A1事件发生的概率*在A1事件发生的情况下B事件发生的概率+A2……
一般来说,概率DP找到正确的状态定义后,转移是比较容易想到的。但状态一定是“可数的,把有范围的整数作为数组下标。事实上,将问题直接作为状态是最好的。如问“人做X事的期望次
【例题】
- 给定一副卡片,这幅卡片一共有k种,小明的钱足够买n张卡片,问n张能买到不同卡片的种类数的期望值
1 |
|
- 给定一副卡片,这幅卡片一共有k种,小明想道买完k种需要买多少张卡片
1 |
|
本部分算法实现与例题解决实现代码链接:点击此处
区间DP
【概念】:可以将一个大区间的问题拆成若干个子区间合并的问题,两个连续的子区间可以进行整合、合并成一个大区间
【实现】:
- 从小到大枚举区间长度。
- 对于每一个区间长度,枚举该长度的每一个区间。
- 对于每一个区间,枚举所有可能出现的两个子区间的组合。
- 对于每一个子区间的组合,计算出合并所需代价。
- 求出当前区间的最优值。例如令
f[i][j]为区间[l,r]的最大价值,则
【例题】:
分析:令为将区间[i,j]合并为一堆的最小花费,那么可以枚举所有的中间点k将区间[i,j]分成[i,k]和[k+1,j]两部分。那么就是先将[i,k]合并为一堆,再将[k+1,j]合并为一堆,最后将这两堆合并成[i,j]的最小花费。在所有的[i,k]和[k+1,j]合并中选一个总价值最小的作为合并[i,j]的答案,即。转移方程$f[i][j]=min{f[i][k]+f[k+1][j]+sum(i,j) | i≤k<r} $
分析:对于区间[l,r]考虑其端点处的颜色,只有端点颜色相同和不同两种情况。可以枚举k作为分界,将整个区间拆分成[l,k]和[k+1,r]两个区间分别涂色,得到不同情况下的转移方程
如果一个字符串是回文串,那么两边+相同的字符依然是回文串,那么令为将区间[l,r]变成回文串的最小花费,如果s[l]=s[r],即当前串两端字符相同,那么
如果不是的话,可以先将A[…]E这样的通常的字符串拆分成单独的A和[…]E,先将后者修改为回文串,然后考虑删去A或者是在后者+A,最后选择最便宜的操作即可,即 得到相应的转移方程,写代码即可
环形DP:前面介绍的都是普通DP,而环形DP与普通区间DP的区别只在于环形区间DP的区间是首尾相连的
【实现】
- 数据的处理方法是将原区间复制一份在后边,总长度×2.
- 枚举的方法与普通区间DP一致。
- 统计答案时要枚举所有的答案区间,找出最优答案。
【例题】:
本部分算法实现与例题解决实现代码链接:点击此处
树形DP
换根DP
【概念】换根DP:以树上的不同点作为根,其解不同,无法通过一次搜索完成答案的求解,因为一次搜索只能得到一个节点的答案。题目描述大致如:一棵树求以哪一个节点为根的时候,xxx最大/最小。先以树形DP的形式求出以某一个点为根的时候的答案(一般都是以1为根的时候),然后再进行一次自上而下的DFS计算答案。也就是说,分两步,1.树形DP 2.在进行第二次DFS时,两个点之间的关系。
【例题】:给定一个个点的无根树,问以树上哪个节点为根时,其所有节点的深度和最大?深度:节点到根的简单路径上边的数量 n<=1e5
如果我们假设某个节点为根,将无根树化为有根树,在搜索回溯时统计子树的深度和,则可以用一次搜索算出以该节点为根时的深
度和,其时间复杂度为O(n)如果我们每个点都这么求,则n^2.
所以我们考虑在第二次搜索时就完成所有节点答案的统计.我们假设第一次搜索时的根节点为1号节点,则此时只有1号节点的答案是已知的。同时第一次搜索可以统计出所有子树的大小。第二次搜索依旧从1号节点出发,若1号节点与节点x相连,则我们考虑能否通过1号节点的答案去推出节点x的答案。我们假设此时将根节点换成节点x,则其子树由两部分构成,第一部分是其原子树,第二部分则是1号节点的其他子树。根从1号节点变为节点x的过程中,我们可以发现第一部分的深度降低了1,第二部分的深度则上升了1,而这两部分节点的数量在第一次搜索时就得到了。即
- 给定一棵个点的无根树,点带权,边带权,求一个点,使得其他点到这个点的距离和最小。其中距离:a->b的距离为a的点权乘以a->b的路径长度
本部分算法实现与例题解决实现代码链接:点击此处
路径相关树形DP
【例题引入】:给你一个n(1≤n≤2000)个点的树。给你m(1≤n≤2000)条树上的简单路径,每个路径有个权值.要求选择一些路径,使得每个点至多在一条路径上,并且路径的权值和最大。
【实现方案】:
思路1
表示以i为根节点的子树中,选择了通过节点i的路径j的最大路径权值和。 g[i]表示节点i没向i上面延伸出去的最优解。
转移方程如下:
- j=0,i不在任何路径中,
- j!=0,i在路径j上,
思路2
f[i]表示节点i没向i上面延伸出去的最优解。
转移方程如下
- i不在任何路径中,
- 考虑i在路径j上且为最高点,考虑将路径j删去,把剩下的若干个子树的f值求和再加上该路径的权值即可
实现代码如下
1 |
|
【例题引入】:给你一个(1≤n≤2000)个点的树。给你m(1≤m≤2000)条树上的简单路径,每个路径有个权值.。这里保证每条路径都是从一个点到它的祖先(也就是根节点)。要求选择一些路径,使得每个点至少在一条路径上,并且路径的权值和最小。如果不存在,输出-1。
分析:以节点i为根的子树中全部被覆盖,且往根最高延伸到深度j的节点的最小代价。相当于每条路径在最低点考虑。其转移方程为
- 假设不选择以i为最低点的路径,
- 对于每一条以i为最低点的路径v,
自下而上的树形DP
【例题引入】:给一颗有根树,每个点都有一个权值i,要选择一些点使得权值利最大,且一个点若被选择,其儿子不能被选择,问最大值。其中(
这类题目通常树形dp状态设定,用一维表示当前子树,但这里题目要求儿子结点和自己不能同时选择,因此对于每个结点,选不选择影响着儿子节点,所以多开一维记录选没选。分类处理一下即可。形式化一点来讲,设表示当前点不选的最大值,表示当前点选了的最大值。
【例题】
- 给一棵树和背包体积v,每个点有一个权值wi,和体积vi,要求选些点权值最大,且体积和不超过背包容量,一个点被选,儿子不能选,求最大值。其中
设表示u这颗子树用了v体积且选了u这个点的最大价值。枚举子树,进行合并转移即可
本部分算法实现与例题解决实现代码链接:点击此处
自下而上的树形DP
【例题引入】:最大独立集问题 蓝桥公司一共有n名员工,编号分别为1~n。他们之间的关系就像一棵以董事长为根的树,父节点就是子节点的直接上司。每个员工有一个快乐指数ai.现蓝桥董事会决定举办一场蓝桥舞会来让员工们在工作之余享受美好时光,不过对于每个员工,他们都不愿意与自己的直接上司一起参会。董事会希望舞会的所有参会员工的快乐指数总和最大,请你求出这个最大值。其中
分析:选择若干个点,使得没有相邻的两个点均被选择。最大化被选择的点的点权和。
其状态为:表示在以u为根节点的子树中选择两两不相邻的若干个点,不选点u的最大权值和。表示在以u为根节点的子树中选择两两不相邻的若干个点,选了点u的最大权值和。
转移方程为
;;
最终得到的答案为
【例题】
本部分算法实现与例题解决实现代码链接:点击此处
数位DP
【概念】:数位DP往往都是这样的题型,给定一个闭区间[l,r],让你求这个区间中满足某种条件的数的总数。所谓数位dp.就是对数位讲行dp.也就是个位、十位等
【实现】
最常用的枚举方式是控制上界枚举,即控制上界枚举就是要让正在枚举的这个数不能超过上界,我们常常利用一个bool变量limit来表明该数位前的其他数位是否恰好都处于最大状态。如果目前这个数不是这个位置最大的数字,那么可取的范围为0-9,否则范围将被限制在该数位在上界中的最大值。(注意,前导零要根据题目特殊处理)
【例题】
数位dp解决不用记忆化搜索这个题是在一个区间里找个数所以我们考虑用前缀和的思想只需找出1~m,1n各自的个数再相减就行了
设为长度为i中最高位是j的windy数的个数方程其中abs(j-k)>=2,枚举数位并转移即可。
其他待后续补充
本部分算法实现与例题解决实现代码链接:点击此处
状压DP
【概念】状态压缩:状态压缩就是使用某种方法来表示某种状态,通常是用一串01数字(二进制数)来表示各个状态。这就要求使用状态压缩的对象的状态必须只有两种,0或1(之前的二进制优化就是使用了此思想);当然如果有三种状态用三进制来表示也未尝不可。
【例题】
像这种题目中要求保留状态的就要考虑状压dp优化,定义状态:为得到组合i的最少糖果包数,即答案为,往组合i中加入一包糖果,得到新的组合j,则从i到j需要包数+1。若原来的,本来就大于,说明找到了更优解法,更新即可。
本部分算法实现与例题解决实现代码链接:点击此处
参考
- 力扣刷题攻略 读者可以在这里参考刷题。
- 蓝桥云课C++班,作者谢子杨
 微信(WeChat)
微信(WeChat) PayPal(点击图片跳转 Click on the image to jump)
PayPal(点击图片跳转 Click on the image to jump)



