算法高阶
本部分算法难度较高,建议读者充分掌握算法基础之后再来学习。
目前以视频的方法为主,等蓝桥杯考完之后按照labuladong或者是考研的方法写代码。
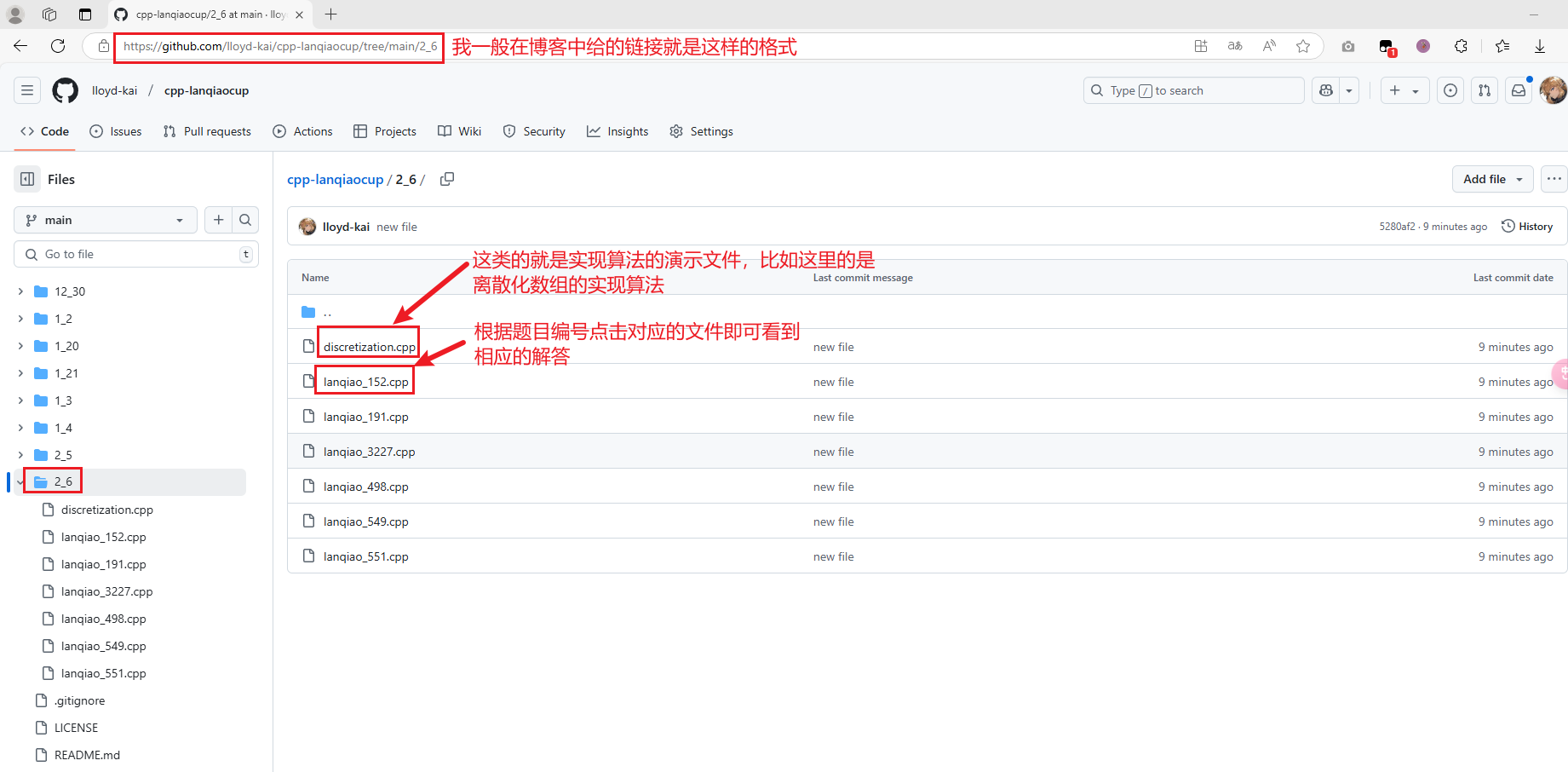
我的仓库使用指南
我的仓库链接格式如下:https://github.com/lloyd-kai/cpp-lanqiaocup/tree/main/1_20 其中1_20表示的是日期(一般是2025),里面的文件就包含对应题目的解答(均通过对应题目的测试)或者是算法实现,其中文件名lanqiao表示 是蓝桥杯官网上的题目 ,_ 后面的数字是蓝桥杯的题目编号 ,可以找到对应的蓝桥杯的题目,比如题目链接是https://www.lanqiao.cn/problems/498/learning/?page=1&first_category_id=1&problem_id=498 problems斜杠后面的数字498 就是对应的题目编号,你就在我指定链接下面的文件夹下按照lanqiao_题目编号.cpp 这样的格式找对应文件,就可以看到对应题目的解答代码。
字符串
01trie
【概念】:01字典树(01-tri)是一种特殊的字典树,它的字符集只有{0,1},主要用来解决一些关于二进制上的问题,例如异或问题和子集问题
【例题引入】:给定n个数,求a i ⨁ a j a_i \bigoplus a_j a i ⨁ a j n ≤ 2 × 10 4 , a i ≤ 10 9 n \leq 2 \times 10^4, a_i\leq 10^9 n ≤ 2 × 1 0 4 , a i ≤ 1 0 9
将数组中所有正整数的二进制表示,按照从高位到低位的顺序,当作字符串挂载在tie树上,然后贪心的走,每一次走跟当前位相反的一位就可以了
KMP和字符串Hash
【概念】:KMP算法是一种字符串匹配算法(在数据结构中有专门的篇章介绍此算法 ),用于匹配模式串P在文本串S中出现的所有位置。例如S=“ababac’”,P=“aba”,那么出现的所有位置是13.在算法中,我们只需要记住和学会使用模板 即可,对其原理只需简单理解,不要过度深究,避免把自己绕进去,可以课后自己慢慢去画图理解。KMP算法将原本O(n^2)的字符串匹配算法优化到了O(n),其精髓在于next数组,next数组表示此时模式串下标失配时应该移动到的位置 ,也表示最长的相同真前后缀的长度 。
【实现】
示例模板如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <bits/stdc++.h> using namespace std;const int N = 1e6 +9 ;char s[N],p[N];int nex[N];int main () ios::sync_with_stdio (0 ),cin.tie (0 ),cout.tie (0 ); cin>>p; int m = strlen (p+1 ); cin>>s; int n = strlen (s+1 ); nex[0 ] = nex[1 ] = 0 ; for (int i =2 ,j=0 ;i<=m;i++) { while (j&&p[i]!=p[j+1 ]) { j=nex[j]; } if (p[i] == p[j+1 ]) { j++; } nex[i] = j; } int ans = 0 ; for (int i = 1 ,j=0 ;i<=n;i++) { while (j && s[i]!=p[j+1 ]) { j = nex[j]; } if (s[i] == p[j+1 ]) { j++; } if (j == m) { ans++; } } cout<<ans; return 0 ; }
【例题】:
这一题基本上就是靠KMP算法的模板就能实现
字符串Hash
【概念】:(基于进制的)字符串Hash本质上是用一个数字表示一段字符串(字符串与数字的映射关系 ),从而降低字符串处理的复杂度。这个数字是一个很大的数字,采用unsigned longlong类型,可以自然溢出,从而简化了取模的部分。还需要一个进制数base,用于规定这个数字的进制。Hash数组h[i]表示字符串s[1~i]的Hash值,采用类似前缀和的形式以便于求出任意一个子串的Hash值。
【实现】
字符串Hash的初始化
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> typedef unsigned long long ull;const ull base = 131 ;const int N = 1e5 + 9 ;ull h[N]; char s[N];for (int i = 1 ; i <= n; i++){ h[i] = h[i - 1 ] * base + s[i - 'A' + 1 ]; }
获取子串s[l]-s[r]的Hash(利用前缀和的性质)
1 2 3 4 ull getHash (int l,int r) return h[r]-h[l-1 ]*b[r-l+1 ]; }
【例题】
这里采用hash的方法求解,枚举所有匹配起点,然后利用hash直接判断查找即可。
本部分算法实现与例题解决实现代码链接:点击此处
回文串
【概念】:回文串:类似ABA,ABCBA,AABBAA等的对于每个i具有sl=s[n+1-i]的字符串。回文半径:对于一个回文中心,如果它的半径为r,如果它为奇数长度的回文串的中心,则说明[i-r+1,i+r-1]为一个回文串。如果i是偶数长度的回文中心,则回文半径没有意义(Manacher算法会解决这个问题)
回文的递归性质:某个点的回文半径相比关于某个回文中心的点的回文半径一定相等或更大。举个例子,对于回文串ABACABAC,第二个B的回文半径至少是第一个B的回文半径。
【实现】:为了解决偶数长度回文半径没有意义的问题,Manacher发明了一种算法,他将所有的回文串都转化为了奇数长度的回文串 。方法就是在字符串中间和头尾插入特殊字符,例如原字符串为ABBA,转换后变为^#A#B#B#A#$,于是我们就可以得到^#A#B#B#A#$中两个B之间的#的回文半径为5,它就表示在原字符串中的回文半径为5-1=4(这个原因待会儿会解释)。字符串中每个位置作为回文中心的回文半径 的算法。位置的回文半径以p[i]表示,意思是在转换后的字符串中[i-p[i]+1,i+p[i]-1]是回文的。
转换后的字符串中回文半径为p[i](必然为偶数),说明在转换前的回文串中回文半径为p[i]-1,转换前的回文串长度为p[i]-1。推导公式为
[ p i + p i − 1 2 ] = [ p i − 1 2 ] = p i − 1 [\frac{p_i+p_i-1}{2}]=[p_i-\frac{1}{2}]=p_i-1 [ 2 p i + p i − 1 ] = [ p i − 2 1 ] = p i − 1
转换后的字符串的有效区间为为[1,2 * n+1],所以我们从1到2*n+1去遍历所有点。如果i<R说明i存在关于C(C是此时最右侧的R所对应的对称中心)的对称点2C-i,那么p就可以等于p[2C-i],当然为了防止越界,要和R-i取小。如果i>=R说明已经无法通过C找到对称点了,因为此时i不在C的回文区间中,就不存在回文的递归性质。
【例题】
本部分算法实现与例题解决实现代码链接:点击此处
字典树
【例子引入】:给n个字符串s1-sn,再给1个字符串t,如何快速查找t是否在s出现过?朴素的方法是循环遍历s1~sn,并比较si是否和t相等即可。这样做对于每一次询问的时间复杂度为O(),如果t的数量较多(即询问次数较多),则会超时。当然前面介绍过KMP算法可以解决此问题,不过我们接下来要介绍的是用字典树的方式解决问题。
【概念】:字典树也叫Trie树,是一种树形结构,其中每个结点上可以存储(当然也可以不存储)一些变量用于表示该字符串的数量(右图中结点上的数字表示结点编号),每条边表示一个字符。假如结点9里面存储一个变量cnt=3,说明存在3个字符串为“cbc”每个结点仅存在一条到根节点的路径,这条路径上的所有边就表示一条字符串。
【实现】
建立字典树
1 2 3 4 int nex[N][27 ];int cnt[N] ;int idx = 2 ;
编写一个insert函数,用于将一个字符串s加入到字典树中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void insert (char s[]) int n = strlen (s+1 ); int x = 1 ; for (int i = 1 ;i<=n;i++) { if (!nex[x][s[i]-'a' ]]) { nex[x][s[i]-'a' ]] = idx++; } x = nex[s][s[i]-'a' ]]; } cnt[x]++; }
编写一个check函数,用于判断某个字符在trie中的出现次数
1 2 3 4 5 6 7 8 9 10 int check (char s[]) int n = strlen (s+1 ); int x = 1 ; for (int i = 1 ;i<=n;i++) { x = nex[x][s[i]-'a' ]; } return cnt[x]; }
【例题】
本部分算法实现与例题解决实现代码链接:点击此处
数学与算法
费马小定理
注意这里的重点不在于费马小定理,而是后面的逆元思想
【概念】:若p为质数,且gcd(a,p)=1(翻译以下就是两数的最大公约数为1,即两数互质 ),则有a p − 1 = 1 ( m o d p ) a^{p-1} = 1 \pmod p a p − 1 = 1 ( mod p )
因为p是一个质数,所以对于任意<p的正整数a,都有gcd(a,p)=1 。般来讲题目给的模数都是一个质数,从而满足费马小定理,可以使用费马小定理来求逆元。
【概念】:逆元 :如果a × c = 1 ( m o d p ) a \times c= 1 \pmod p a × c = 1 ( mod p ) a − 1 a^{-1} a − 1 逆元是一个整数 。对费马小定理的式子两边同时除以一个a,得到a p − 2 = a p − 1 × a − 1 ; c = 1 ( m o d p ) × a − 1 ; a p − 1 = 1 ( m o d p ) ; = > a p − 2 = 1 a a^{p-2} =a^{p-1}\times a^{-1};c=1 \pmod p \times a^{-1};a^{p-1}=1 \pmod p; =>a^{p-2}= \frac{1}{a} a p − 2 = a p − 1 × a − 1 ; c = 1 ( mod p ) × a − 1 ; a p − 1 = 1 ( mod p ) ; => a p − 2 = a 1
1 2 3 4 ll inv (ll x) return qmi (x,p-2 ); }
【例题】
首先特判k=0时,1号获胜。然后k为奇数时,所有偶数号的选手平摊获胜概率。k为偶数时,所有奇数号选手平摊获胜概率。然后计算n有多少个偶数和奇数就可以了。当然这里要用到逆元的思想
本部分算法实现与例题解决实现代码链接:点击此处
高斯消元法
【概念】高斯消元法是一个用来求解线性程组的算法,在线性代数里面有专门的计算部分,而这里的高斯消元法就是用计算机去模拟人使用高斯消元法的步骤。
PS:因为我学过数值计算(研究生课程),里面就专门介绍如何用Python实现高斯消元法,是通过多次迭代+取值实现的
高斯消元的目的是,先进行加减消元,然后我们可以先求得一个未知数的值,然后可以逐层往回代,也就是代入消元法,依次可以得到定第2个、第3个未知数的值,以至第个未知数。最终解出方程组中各个未知数。
演示如下
给定一个线性方程组:{ 2 x + 4 y − 2 z = 2 4 x + 9 y − 3 z = 8 − 2 x − 3 y + 7 z = 10 \begin{cases}2x + 4y - 2z = 2 \\4x + 9y - 3z = 8 \\-2x - 3y + 7z = 10\end{cases} ⎩ ⎨ ⎧ 2 x + 4 y − 2 z = 2 4 x + 9 y − 3 z = 8 − 2 x − 3 y + 7 z = 10
我们可以将其表示为增广矩阵的形式:[ 2 4 − 2 ∣ 2 4 9 − 3 ∣ 8 − 2 − 3 7 ∣ 10 ] \begin{bmatrix}2 & 4 & -2 & | & 2 \\4 & 9 & -3 & | & 8 \\-2 & -3 & 7 & | & 10\end{bmatrix} 2 4 − 2 4 9 − 3 − 2 − 3 7 ∣ ∣ ∣ 2 8 10
将第一列的下三角部分变为零。
[ 2 4 − 2 ∣ 2 0 1 1 ∣ 4 0 1 5 ∣ 12 ] \begin{bmatrix}
2 & 4 & -2 & | & 2 \\
0 & 1 & 1 & | & 4 \\
0 & 1 & 5 & | & 12
\end{bmatrix} 2 0 0 4 1 1 − 2 1 5 ∣ ∣ ∣ 2 4 12
将第二列的下三角部分变为零。
[ 2 4 − 2 ∣ 2 0 1 1 ∣ 4 0 0 4 ∣ 8 ] \begin{bmatrix}
2 & 4 & -2 & | & 2 \\
0 & 1 & 1 & | & 4 \\
0 & 0 & 4 & | & 8
\end{bmatrix} 2 0 0 4 1 0 − 2 1 4 ∣ ∣ ∣ 2 4 8
通过回代求解未知数。
4 z = 8 ⇒ z = 2 ; 4z = 8 \Rightarrow z = 2; 4 z = 8 ⇒ z = 2 ; y + 2 = 4 ⇒ y = 2 ; y + 2 = 4 \Rightarrow y = 2; y + 2 = 4 ⇒ y = 2 ; 2 x + 4 × 2 − 2 × 2 = 2 ⇒ 2 x + 8 − 4 = 2 ⇒ 2 x = − 2 ⇒ x = − 1 2x + 4 \times 2 - 2 \times 2 = 2 \Rightarrow 2x + 8 - 4 = 2 \Rightarrow 2x = -2 \Rightarrow x = -1 2 x + 4 × 2 − 2 × 2 = 2 ⇒ 2 x + 8 − 4 = 2 ⇒ 2 x = − 2 ⇒ x = − 1
高斯消元法通过逐步消元,将线性方程组转化为上三角矩阵 ,然后通过回代求解未知数。这种方法适用于任何可逆的线性方程组 。
如果用暴力枚举来消元,示例代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <iostream> using namespace std;const int MAXN = 510 ;int n;double a[MAXN][MAXN];int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= n + 1 ; j++) { scanf ("%1f" , &a[i][j]); } } for (int i = 1 ; i <= n; i++) { int maxx = i; for (int j = i + 1 ; j <= n; j++) { if (fabs (a[j][i]) > fabs (a[maxx][i])) { maxx = j; } } for (int j = 1 ; j <= n + 1 ; j++) { swap (a[i][j], a[maxx][j]); } if (!a[i][i] == 0 ) { continue ; } double k = a[i][i]; for (int j = 1 ; j <= n; j++) { if (j != i) { for (int k = i + 1 ; k <= n + 1 ; k++) { a[j][k] -= a[i][k] * a[j][i] / k; } } } } for (int i = 1 ; i <= n; i++) { printf ("%.2lf\n" , a[i][n + 1 ] / a[i][i]); } return 0 ; }
而使用高斯消元法的算法实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <iostream> using namespace std;const int MAXN = 510 ;int n;double a[MAXN][MAXN], ans[MAXN];int solve (int n, int m) for (int i = 1 ; i <= n; i++) { int r = i; for (int j = i + 1 ; j <= n; j++) { if (fabs (a[r][i]) < fabs (a[j][i])) { r = j; } } if (fabs (a[r][i])) { continue ; } for (int j = 1 ; j <= n + 1 ; j++) { swap (a[i][j], a[r][j]); } double div = a[i][i]; for (int j = 1 ; j <= n + 1 ; j++) { a[i][j] /= a[i][i]; } for (int j = i + 1 ; j <= n; j++) { div = a[j][i]; for (int k = i; k <= n + 1 ; k++) { a[j][k] -= a[i][k] * div; } } } ans[n] = a[n][n + 1 ]; for (int i = n - 1 ; i >= 1 ; i--) { ans[i] = a[i][n + 1 ]; for (int j = i + 1 ; j <= n; j++) { ans[i] -= (a[i][j] * ans[j]); } } for (int i = 1 ; i <= n; i++) { printf ("%.2lf\n" , ans[i]); } return 0 ; } int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= n + 1 ; j++) { scanf ("%lf" , &a[i][j]); } } int guass = solve (n, n); return 0 ; }
高斯消元完成后,若存在系数全为0、常数不为0的行,则方程组无解。
若系数不全为0的行恰好有n个,则主元有n个,方程组有唯一解。
系数不为0的行<n个,则有无数个解。
【例题】
一个球体上的所有点到球心距离相等,因此我们只需求出一个点(x 1 , x 2 , x 3 . . . . x n x_1,x_2,x_3....x_n x 1 , x 2 , x 3 .... x n ∑ j = 0 n ( a i , j − x j ) 2 = C \sum_{j=0}^{n}(a_{i,j}-x_j)^2=C ∑ j = 0 n ( a i , j − x j ) 2 = C
∑ j = 1 n ( a i , j 2 − a i + 1 , j 2 − 2 x j ( a i , j − a i + 1 , j ) ) = 0 \sum_{j=1}^{n}(a_{i,j}^{2}-a_{i+1,j}^{2}-2x_j(a_{i,j}-a_{i+1,j}))=0 ∑ j = 1 n ( a i , j 2 − a i + 1 , j 2 − 2 x j ( a i , j − a i + 1 , j )) = 0
2 x j ( a i , j − a i + 1 , j ) = ∑ j = 1 n ( a i , j 2 − a i + 1 , j 2 ) ( i = 1 , 2 , 3... n ) 2x_j(a_{i,j}-a_{i+1,j})=\sum_{j=1}^{n}(a_{i,j}^{2}-a_{i+1,j}^{2})(i=1,2,3...n) 2 x j ( a i , j − a i + 1 , j ) = ∑ j = 1 n ( a i , j 2 − a i + 1 , j 2 ) ( i = 1 , 2 , 3... n )
套用前面的模板,加上一个二维的数组就基本可以解决
有两种情况,如果一只鸟有偶数个朋友,那么只需要保证有偶数个,朋友在上游,就会有偶数个朋友在下游,这只鸟去哪里都可以。如果这只鸟有奇数个朋友,那么就要保证这只鸟去有偶数个朋友的区域。用xi=0表示去下游,xi=1表示去上游
对于有偶数个朋友的鸟:x a 1 ⨁ x a 2 ⨁ x a 3 . . . . ⨁ x a m = 0 x_{a1} \bigoplus x_{a2} \bigoplus x_{a3}....\bigoplus x_{am}=0 x a 1 ⨁ x a 2 ⨁ x a 3 .... ⨁ x am = 0
对于有奇数个朋友的鸟:x a 1 ⨁ x a 2 ⨁ x a 3 . . . . ⨁ x a m ⨁ x i = 1 x_{a1} \bigoplus x_{a2} \bigoplus x_{a3}....\bigoplus x_{am} \bigoplus x_{i}=1 x a 1 ⨁ x a 2 ⨁ x a 3 .... ⨁ x am ⨁ x i = 1
本部分算法实现与例题解决实现代码链接:点击此处
矩阵乘法、整除、同余、LCM和GCD
矩阵乘法
【概念】:矩阵的乘法在线性代数中有详细的介绍,不懂的去看宋浩的课(❁´◡`❁)。这里补充几点。
每个矩阵有一个行数和一个列数,只有当相乘的两个矩阵的左矩阵的列数等于右矩阵的行数时,才能相乘,否则不允许做矩阵乘法。
矩阵乘法的规则用计算机语言描述就是,第一个矩阵A的第i行和第二个矩阵B的第j列的各M个元素对应相乘再相加得到新矩阵C[i][j]的值。
【例题】
本部分算法实现与例题解决实现代码链接:点击此处
整除
【概念】:在计算机中,整数之间的除法往往是整除且向下取整的,例如:[ 12 5 ] = 2 [\frac{12}{5}]=2 [ 5 12 ] = 2
如果要向上去整呢?如果要计算x/y向上取整,需要改写式子为(x+y-1)/y或(x-1)/y+1。其中如果x可以被y整除,记作y ∣ x y|x y ∣ x
整除的性质如下
a ∣ b ⟺ − a ∣ b ⟺ a ∣ − b ⟺ ∣ a ∣ ∣ ∣ b ∣ a|b \Longleftrightarrow -a|b \Longleftrightarrow a|-b \Longleftrightarrow |a|||b| a ∣ b ⟺ − a ∣ b ⟺ a ∣ − b ⟺ ∣ a ∣∣∣ b ∣ a ∣ b ∧ b ∣ c ⟹ a ∣ c a|b \land b|c \Longrightarrow a|c a ∣ b ∧ b ∣ c ⟹ a ∣ c ^是逻辑与 在离散数学中是且的意思 a ∣ b ∧ b ∣ c ⟺ ∀ x , y ∈ Z , a ∣ ( x b + y c ) a|b \land b|c \Longleftrightarrow \forall x,y \in Z,a|(xb+yc) a ∣ b ∧ b ∣ c ⟺ ∀ x , y ∈ Z , a ∣ ( x b + yc ) a ∣ b ∧ b ∣ a ⟹ b = ± a a|b \land b|a \Longrightarrow b=\pm a a ∣ b ∧ b ∣ a ⟹ b = ± a i f m ≠ 0 , t h e n a ∣ b ⟺ m a ∣ m b if \quad m \neq0,then \quad a|b \Longleftrightarrow ma|mb i f m = 0 , t h e n a ∣ b ⟺ ma ∣ mb i f b ≠ 0 , t h e n a ∣ b ⟹ ∣ a ∣ ≤ ∣ b ∣ if \quad b \neq0,then \quad a|b \Longrightarrow |a|\leq |b| i f b = 0 , t h e n a ∣ b ⟹ ∣ a ∣ ≤ ∣ b ∣ i f a ≠ 0 , b = q a + c , t h e n a ∣ b ⟺ a ∣ c if \quad a \neq0,b=qa+c,then \quad a|b \Longleftrightarrow a|c i f a = 0 , b = q a + c , t h e n a ∣ b ⟺ a ∣ c
同余
【概念】:意思是两个或多个数字x,对于一个模数M的余数是相等的 ,或者说在模M意义下,他们是相等的。例如当M=7,x=[1,8,15,8,50]是同余的,这些x有一个共同的关系,就是x%M=1。
同余的性质:
自反性:a ≡ a ( mod m ) a \equiv a (\text{mod } m) a ≡ a ( mod m )
对称性:若a ≡ b ( mod m ) a \equiv b (\text{mod } m) a ≡ b ( mod m ) b ≡ a ( mod m ) b \equiv a (\text{mod } m) b ≡ a ( mod m )
传递性:若a ≡ b ( mod m ) a \equiv b (\text{mod } m) a ≡ b ( mod m ) b ≡ c ( mod m ) b \equiv c (\text{mod } m) b ≡ c ( mod m ) a ≡ c ( mod m ) a \equiv c (\text{mod } m) a ≡ c ( mod m )
线性运算:
若a , b , c , d ∈ Z a, b, c, d \in \mathbb{Z} a , b , c , d ∈ Z m ∈ N ∗ m \in \mathbb{N}^* m ∈ N ∗ a ≡ b ( mod m ) a \equiv b (\text{mod } m) a ≡ b ( mod m ) c ≡ d ( mod n ) c \equiv d (\text{mod } n) c ≡ d ( mod n )
a ± c ≡ b ± d ( mod m ) a \pm c \equiv b \pm d (\text{mod } m) a ± c ≡ b ± d ( mod m ) a × c ≡ b × d ( mod m ) a \times c \equiv b \times d (\text{mod } m) a × c ≡ b × d ( mod m )
若a , b ∈ Z a, b \in \mathbb{Z} a , b ∈ Z k , m ∈ N ∗ k, m \in \mathbb{N}^* k , m ∈ N ∗ a ≡ b ( mod m ) a \equiv b (\text{mod } m) a ≡ b ( mod m ) a k ≡ b k ( mod m k ) a k \equiv b k (\text{mod } mk) ak ≡ bk ( mod mk )
若a , b ∈ Z a, b \in \mathbb{Z} a , b ∈ Z d , m ∈ N ∗ d, m \in \mathbb{N}^* d , m ∈ N ∗ d ∣ a , d ∣ b , d ∣ m d | a, d | b, d | m d ∣ a , d ∣ b , d ∣ m a ≡ b ( mod m ) a \equiv b (\text{mod } m) a ≡ b ( mod m ) a d ≡ b d ( mod m d ) \frac{a}{d} \equiv \frac{b}{d} (\text{mod } \frac{m}{d}) d a ≡ d b ( mod d m )
若a , b ∈ Z a, b \in \mathbb{Z} a , b ∈ Z d , m ∈ N ∗ d, m \in \mathbb{N}^* d , m ∈ N ∗ d ∣ m d | m d ∣ m a ≡ b ( mod m ) a \equiv b (\text{mod } m) a ≡ b ( mod m ) a ≡ b ( mod d ) a \equiv b (\text{mod } d) a ≡ b ( mod d )
GCD和LCM
【概念】:GCD(Greatest Common Divisor)是最大公约数,LCM(Least Common Multiple)是最小公倍数。大多数情况下,我们更关注GCD,如果题目和LCM有关,也通常会转换成和GCD相关的(前面费马小定理介绍过 )
这里简单介绍一下实现方法
1 2 3 4 5 int gcd (int a,int b) return b == 0 ?a:gcd (b,a%b); }
简单地理解一下,首先不妨设a<b,有gcd(a,b)=gcd(a,b-a=gcd(a,b-2a=gcd(a,b%a),b%a<a,于是将他们两个调换位置,继续向下递归,直到b变为0,gcd(x,0)=x。
LCM的实现方法
1 2 3 4 int lcm (int a,int b) return a/gcd (a,b)*b; }
【例题】
本部分算法实现与例题解决实现代码链接:点击此处
快速幂原理
【概念】:朴素的计算a的b次方的方法,所需的时间复杂度为O(b),即用一个循环,每次乘一个a,乘b次。利用倍增的思想,可以将求幂运算的时间复杂度降低为O(logb).当b为偶数:a b = a b 2 × a b 2 = ( a 2 ) b 2 a^b=a^{\frac{b}{2}} \times a^{\frac{b}{2}}= (a^2)^{\frac{b}{2}} a b = a 2 b × a 2 b = ( a 2 ) 2 b a b = a × a b 2 × a b 2 = a × ( a 2 ) b 2 a^b=a\times a^{\frac{b}{2}} \times a^{\frac{b}{2}}= a\times(a^2)^{\frac{b}{2}} a b = a × a 2 b × a 2 b = a × ( a 2 ) 2 b
求幂本质是求乘法,但是在乘法器中求乘法时间会很长,学过微机原理的同学应该有所体会,所以需要对求幂进行优化
【实现】:实现方法如下,以后记住,qmi就是快速幂函数 ,一旦题目中讲到幂的运算或者是取模,就要优先考虑是否使用快速幂 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int qmi (int a,int b,int p) int res = 0 ; while (b) { if (b&1 ) { res = res*a%p; } a=a*a; b>>=1 ; } return res; }
【例题】
本部分算法实现与例题解决实现代码链接:点击此处
欧拉函数与欧拉降幂
【概念】:欧拉函数phi(n)表示<=n的且与n互质的数的个数,按照定义有phi(1)=1。ϕ ( n ) = n ( 1 − 1 p 1 ) ( 1 − 1 p 2 ) … ( 1 − 1 p m ) \phi(n)=n(1-\frac1{p_1})(1-\frac1{p_2})\ldots(1-\frac1{p_m}) ϕ ( n ) = n ( 1 − p 1 1 ) ( 1 − p 2 1 ) … ( 1 − p m 1 )
其中p1~pm是对n进行唯一分解之后的质因子。n = p 1 k 1 × p 2 k 2 × … × p m k m n=p_1^{k_1}\times p_2^{k_2}\times\ldots\times p_m^{k_m} n = p 1 k 1 × p 2 k 2 × … × p m k m
【实现】:求phi(n),这个n范围一般是1-le9,我们利用类似唯一分解的框架去枚举所有质因子按照之前的计算公式去计算即可。后面学习线性筛法后可以筛除一段区间内的所有数字的欧拉函数(例如1~1e7的所有数字的欧拉函数)。示例部分代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 using ll = long long ;ll phi = n; for (int i = 2 ;i<=n/i;i++){ if (n%i) { continue ; } phi = phi/i*(i-1 ); while (n%i==0 ) { n/=i; } if (n>1 ) { phi = phi/n*(n-1 ); } }
欧拉降幂
【概念】:首先先介绍欧拉定理,当a,c互质时,有a ϕ ( c ) = 1 ( m o d c ) a^{\phi(c)}=1\pmod c a ϕ ( c ) = 1 ( mod c )
当a,c互质时有:a b = a b mod ϕ ( c ) mod c a^b=a^{b \,\text{mod} \,\phi(c)} \text{mod} \,c a b = a b mod ϕ ( c ) mod c a b = a b mod ϕ ( c ) + ϕ ( c ) mod c a^b=a^{b \,\text{mod} \,\phi(c)+\phi(c)} \text{mod} \,c a b = a b mod ϕ ( c ) + ϕ ( c ) mod c
【例题】
设c=1e9+7,本体题目实际上就是要求n m ! ( m o d c ) n^{m!} \, \pmod c n m ! ( mod c ) n m ! = n m ! mod ϕ ( c ) mod c n^{m!}=n^{m! \,\text{mod} \,\phi(c)} \text{mod} \,c n m ! = n m ! mod ϕ ( c ) mod c
本部分算法实现与例题解决实现代码链接:点击此处
裴蜀定理
【概念】:又称贝祖定理,即a,b为不全为0的整数,则存在整数x,y使得ax+by=gcd(a,b);
这里就不写证明了,证明题就留给数学专业的人做吧(●’◡’●)
【例题引入】:a,b为大于等于0的整数,n为整数,是否存在大于等于0的整数x,y使方程ax+by=n有解?
这里就不推理了,直接写结论
若n>ab-a-b,有解;若n=0;有解;若n<0;无解;若ax+by=n有解,则ax+by=ab-a-b-n无解
【例题】
你看这个题目基本上就是例题引入的模板,直接把a,b替换,然后用性质就可以轻松解决
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> using namespace std;int main () int a,b; cin>>a; cin>>b; cout<<a * b - a - b; return 0 ; }
本部分算法实现与例题解决实现代码链接:点击此处
素数
素数朴素判定与埃氏筛法
【概念】:素数就是质数,素数是指除了1和它本身,没有其他因子的数字,例如7,13,17是质数,而9,14,20不是。为了判断一个数字n是不是质数,我们可以枚举2~-1的所有数字,检查其中是否存在一个数字i可以整除n(即n%i==0),这是暴力枚举的思想。但是我们又知道,如果a*b=n,不妨设a<b,则有a<=sqrt(n),b>=sqrt(n).于是我们只需要从2枚举到sqrt(n)来判断是否存在n的因子即可。
【实现】示例代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <iostream> using namespace std;bool isPrime (int n) if (n < 2 ) { return false ; } for (int i = 2 ; i <= n / i; i++) { if (n % i == 0 ) { return false ; } } return true ; } int main () int num; cin >> num; if (isPrime (num)) { cout << "是素数" << endl; } else { cout << "不是素数" << endl; } }
【例题】
埃氏筛法
【概念】:对于一个合数,它必然存在一个质数的因子,也就是说合数一定是某个较小的质数的倍数。我们知道枚举一个数字n的所有因数是很慢的,是O(sqrt(n)的时间复杂度,那不妨枚举倍数。首先我们知道2是一个质数,然后我们将2的所有大于它本身的倍数都“筛掉” ,因为可以判定它们都不是质数。然后到3、4…,如果枚举到的数字没有被筛掉,说明在[2~i-1]不存在某个数字可以整除,于是就可以直接判定是一个质数 ,然后再将个所有倍数筛掉。这就是埃氏筛法的思想。也就是先把所有的非质数筛掉,剩下的就是质数 。
这种方法适合数据量大的题目
【实现】:示例的部分代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 bool vis[N];vis[0 ]=vis[1 ]=true ; for (int i = 2 ;i<=n;i++){ if (!vis[i]) { for (int j = 2 *i;j<=n;j+=i) { vis[j]=true ; } } }
【例题】
这一题用前面的暴力枚举就会超时,而用埃氏筛选法后再枚举差值判断素数就会好很多
本部分算法实现与例题解决实现代码链接:点击此处
素数筛
【概念】:素数筛法是一种快速“筛”出2~n之间所有素数的方法 。朴素的筛法可以根号判断。
前面我们已经介绍过朴素筛选法和埃氏筛选法,这里我们介绍一个新方法——欧拉筛选法,基本上是埃氏筛选法的优化。
埃氏筛是筛去每个质数的倍数,但难免,会有合数会被其不同的质因子多次重复筛去 。这就造成了时间浪费。核心思想:让每一个合数被其最小质因数筛到,所以,我们不需要用一个fo循环去筛除一个质数的所有倍数,我们将所有质数存储到primes[]中 ,然后枚举到第i个数时,就筛去所有的primes[j]*i。这样就在每一次遍历中,正好筛除了所有已知素数的i倍。但是为了确保合数只被最小质因子筛掉,最小质因子要乘以最大的倍数,即要乘以最大的i,所以不能提前筛,所以如果i%primes[j]==0.我们就结束内层循环!
实际上,对于x,我们遍历到质数表中的p,且发现p|x时,就应当停遍历质数表。具体的证明这里就不写了(●’◡’●)
【实现】:示例代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> using namespace std;const int MAXN = 1e5 + 7 ;int vis[MAXN], isprime[MAXN];int main () int n = 100 ; int cnt = 0 ; for (int i = 2 ; i <= n; i++) { if (!vis[i]) { isprime[++cnt] = i; } for (int j = 1 ; j <= cnt && isprime[j] * i <= n; j++) { vis[isprime[j] * i] = 1 ; if (i%isprime[j] == 0 ) { break ; } } } for (int i = 1 ; i <= cnt; i++) { cout << isprime[i] << ' ' ; } return 0 ; }
【例题】:给定一个区间[a,b],求区间内有多少个素数
示例代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> #include <vector> using namespace std;int countPrimesInRange (int a, int b) if (b < 2 ) return 0 ; vector<bool > isPrime (b + 1 , true ) ; isPrime[0 ] = isPrime[1 ] = false ; for (int i = 2 ; i <= b; ++i) { if (isPrime[i]) { for (int j = 2 * i; j <= b; j += i) { isPrime[j] = false ; } } } int count = 0 ; for (int i = a; i <= b; ++i) { if (isPrime[i]) { ++count; } } return count; } int main () int a, b; cout << "请输入区间的起始值 a 和结束值 b: " ; cin >> a >> b; int primeCount = countPrimesInRange (a, b); cout << "区间 [" << a << ", " << b << "] 内的质数个数为: " << primeCount << endl; return 0 ; }
唯一分解定理
【概念】:唯一分解定理(就是质因数分解 )指的是:对于任意一个>1的正整数,都可以以唯一的一种方式分解为若干质因数的乘积。n = p 1 k 1 × p 2 k 2 × … × p m k m n=p_1^{k_1}\times p_2^{k_2}\times\ldots\times p_m^{k_m} n = p 1 k 1 × p 2 k 2 × … × p m k m
【实现】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;const int N = 2e5 +9 ;vector<pair<int ,int >>v; int main () int x; cin>>x; for (int i = 2 ;i<=x/i;i++) { if (x%i) { continue ; } int cnt = 0 ; while (x%i == 0 ) { cnt++; x/=i; } } if (x>1 ) { v.push_back ({x,1 }); } for (const auto i:v) { cout<<i.first<<' ' <<i.second<<endl; } return 0 ; }
约数个数定理
通过某个数字的唯一分解: x = p 1 k 1 × p 2 k 2 × . . . × p m k m x = p_1^{k_1} \times p_2^{k_2} \times ... \times p_m^{k_m} x = p 1 k 1 × p 2 k 2 × ... × p m k m d ( x ) = ∏ i = 1 m ( k i + 1 ) d(x)=\prod_{i=1}^m(k_i+1) d ( x ) = ∏ i = 1 m ( k i + 1 )
【例题】
100的阶乘约数个数就是所有(质因数的指数+1)的乘积
本部分算法实现与例题解决实现代码链接:点击此处
约数和定理
通过某个数字的唯一分解: x = p 1 k 1 × p 2 k 2 × . . . × p m k m x = p_1^{k_1} \times p_2^{k_2} \times ... \times p_m^{k_m} x = p 1 k 1 × p 2 k 2 × ... × p m k m x x x p 1 2 p1^2 p 1 2 p 1 k 1 p1^{k_1} p 1 k 1 s u m ( x ) = ∏ i = 1 m ∑ j = 0 k i p i j sum(x) = \prod_{i=1}^{m} \sum_{j=0}^{k_i} p_i^j s u m ( x ) = ∏ i = 1 m ∑ j = 0 k i p i j
行列式
【概念】:线性代数第一章的知识点,不懂的看宋浩的线性代数
行列式,记作det A或|A|。行列式定义如下: ∣ A ∣ = ∑ p ( − 1 ) τ ( p ) ∏ i = 1 n a i , p i |A|=\sum_{p}(-1)^{\tau(p)}\prod_{i=1}^{n}a_{i,p_i} ∣ A ∣ = ∑ p ( − 1 ) τ ( p ) ∏ i = 1 n a i , p i 不用记这个公式,按照线性代数中的例子去理解就行 。
【性质】
代数余子式 : 对于行列式|A|将其第行第ⅰ列的所有元素删除,剩下的部分组成的行列式,再乘以( − 1 ) i + j (-1)^{i+j} ( − 1 ) i + j a i , j a_{i,j} a i , j A i , j A_{i,j} A i , j
【定理】:
⭐⭐⭐(重要) 行列式展开:∣ A ∣ = ∑ j = 1 n a i , j A i , j ; |A| = \sum^{n}_{j=1}a_{i,j}A_{i,j}; ∣ A ∣ = ∑ j = 1 n a i , j A i , j ; 0 = ∑ j = 1 n a i , j A k , j 0 = \sum^{n}_{j=1}a_{i,j}A_{k,j} 0 = ∑ j = 1 n a i , j A k , j
矩阵A的某一行(列)乘以k加到另一行(列),其行列式不变
矩阵A的某一行(列)乘以k,行列式的值=k|A|
矩阵A任意两行或两列互换,行列式的值等于其相反数
【实现】
就是前面讲过的高斯消元法,这里我用C++中的vector容器实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 double det (int n, vector<vector<double >> &a, const double EPS) double det = 1 ; for (int i = 0 ; i < n; i++) { int tmp = i; for (int j = i + 1 ; j < n; j++) { if (fabs (a[j][i]) > fabs (a[tmp][i])) { tmp = j; } } if (fabs (a[tmp][i]) < EPS) { det = 0 ; break ; } if (tmp != i) { swap (a[tmp], a[i]); det *= -1 ; } for (int j = 0 ; j < n; j++) { if (j != i && fabs (a[j][i]) > EPS) { double res = a[j][i]; for (int k = i; k < n; k++) { a[j][k] -= a[i][k] * res / a[i][i]; } } } det *= a[i][i]; } return det; }
排列组合
就是高中的组合与全排列,以下不侧重其概念的解释,而是讲解其性质和应用
【性质】:
C n m = n × ( n − 1 ) × ( n − 2 ) × … × ( n − m + 1 ) m × ( m − 1 ) × ( m − 2 ) × … × 1 = n ! ( n − m ) ! m ! C n 0 + C n 1 + C n 2 + … + C n n = 2 n A n n = n ! C n m = C n − 1 m + C n − 1 m − 1 \begin{aligned}
& C_n^m=\frac{n\times(n-1)\times(n-2)\times\ldots\times(n-m+1)}{m\times(m-1)\times(m-2)\times\ldots\times1}=\frac{n!}{(n-m)!m!} \\
& C_n^0+C_n^1+C_n^2+\ldots+C_n^n=2^n\quad A_n^n=n! \\
& C_n^m=C_{n-1}^m+C_{n-1}^{m-1}
\end{aligned} C n m = m × ( m − 1 ) × ( m − 2 ) × … × 1 n × ( n − 1 ) × ( n − 2 ) × … × ( n − m + 1 ) = ( n − m )! m ! n ! C n 0 + C n 1 + C n 2 + … + C n n = 2 n A n n = n ! C n m = C n − 1 m + C n − 1 m − 1
分类加法
在组合计数中,如果可以将要计数的东西划分为多个互不影响的类别,那么在计算出每一类的数量后,最终结果是各类别的数量相加。比如从迷宫入口走到出口一共有几条路,一般来说只要各路径之间不完全重合,符合题意就可以作为一条路,不同的路相加就是总路数。
分类加法的计数原理往往运用在计数dp 中,具体表现在状态转移方程为dp[i]=若干个类别的状态的求和。这种计数dp的状态转移方程就是由分类加法原理 导出的。比如将向下走的和向右边走的分一类,向下走的又可以分成几类,以此类推。
【例题】:
先不要进入到代码中,从做数学题的角度来看,就是要你求符合提议的数,正向考虑比较麻烦,可以考虑反向思考,即总数-不符合题意的数=符合题意的数,即2 n − C n a − C n b − C n 0 2^n-C_n^a-C_{n}^b-C_{n}^{0} 2 n − C n a − C n b − C n 0
通过观察分析我们发现,如果要使得方格染色合法,第一行或第一列一定是两种颜色交替出现的。设集合A:第一行交替出现的方案
分步乘法
原理的出现频率并没有分类加法高,但也依然是十分重要的计数原理**。当为了构造某一个东西需要许多步,且每一步互不影响**、有多种选择时,总的方案数就是各步的选择数的乘积。例如我要求一个整数的因子数量,除了一个个枚举的方法,我们还可以先将其进行唯一分解,然后进行构造。 n = p 1 k 1 × p 2 k 2 × . . . × p m k m n = p_1^{k_1} \times p_2^{k_2} \times ... \times p_m^{k_m} n = p 1 k 1 × p 2 k 2 × ... × p m k m 这种题目你也做过,就是高中的填色问题 。
本部分算法实现与例题解决实现代码链接:点击此处
参考
力扣刷题攻略 读者可以在这里参考刷题。蓝桥云课C++班,作者谢子杨

 微信(WeChat)
微信(WeChat) PayPal(点击图片跳转 Click on the image to jump)
PayPal(点击图片跳转 Click on the image to jump)


